

Proximus EnCo is an API platform exposing a wide range of services in the domains of Telco, IoT, Big Data, Cloud and other disruptive technologies such as blockchain. The challenge is to provide consistent user experience across all services, with the highest possible quality. Error handling is an important aspect of it for all developers using our APIs. To achieve that, we pay attention to Internet standards (e.g. HTTP Status codes) and best practices.
Most common EnCo Proximus errors and how to avoid them
On an average day, for every 100.000 requests, Proximus EnCo returns:
- 14 errors in the HTTP 500 range
- 562 errors in the HTTP 400 range ( 152 in the 400 range and 410 in the 401-403 range)
HTTP 400 errors are mainly related to wrong or incomplete requests, data which couldn’t be found and are likely to be solved by end users. This doesn’t mean Proximus EnCo is not looking at those error types. If there are too many of them, it could mean that our documentation is not clear enough leading to poorly formatted requests, use of deprecated resources, authentication issues, etc. Monitoring the amount of 400 errors (especially for new accounts) is therefore a good indicator of the quality of the documentation and how easily our APIs can be implemented. On the other hand, some error 4xx could also be wrongly labelled. This means that the error is on the server side or that there should be no error returned in the first place. In this case, it is critical that we identify those issues and fix them. Finally not all errors should be looked at in the same way, for example some authentication errors are showing up “by design” as some of our customers choose not to check their token validity before issuing their requests. They will use the error response to get a new token before re-issuing the failed request.
HTTP 401-403 errors are mainly related to access rights and privileges…
HTTP 500 errors are internal server errors which are mainly due to issues in the code. We do our best to get rid of them. These are really considered as “disgraceful errors” by our developers and we can feel the tension rising internally when some of those show up ![]() . More seriously, no system is error-free but it’s good to keep a close eye on those internal errors which can also give a good indication of the overall quality of our APIs and our technical debt. Some errors can be due to our system architecture which may require significant investment to fix, some errors are trivial to fix and some are “exotic”. The first type usually shows up during longer outages which can cause more damage to us and our customers. The last type occurs rarely, almost randomly, and they are a real puzzle to solve for our developers (developers love puzzles, but they love solving them even more!). The goal for the whole EnCo team (product managers, architects, developers, QA engineers, etc;) is then to find the right balance between developing new features and reducing the technical debt.
. More seriously, no system is error-free but it’s good to keep a close eye on those internal errors which can also give a good indication of the overall quality of our APIs and our technical debt. Some errors can be due to our system architecture which may require significant investment to fix, some errors are trivial to fix and some are “exotic”. The first type usually shows up during longer outages which can cause more damage to us and our customers. The last type occurs rarely, almost randomly, and they are a real puzzle to solve for our developers (developers love puzzles, but they love solving them even more!). The goal for the whole EnCo team (product managers, architects, developers, QA engineers, etc;) is then to find the right balance between developing new features and reducing the technical debt.
HTTP 502-504 errors are mainly due to bad gateways, unavailability of systems and services or slow response times resulting in timeouts.
Whenever an error is returned, Proximus EnCo should not only provide the HTTP status code, but also some error details (e.g. response body). Error details are provided in JSON format and typically contain some more information about the error.
Using clear HTTP status codes is key but quality is undeniably achieved through returning meaningful error details. These should be consistent across all our APIs, human-readable and machine-readable.
What guidelines for Error handling?
Before we present our vision for better error handling, what is the current situation at EnCo? First of all, each product or API documentation lists the most frequent errors in their respective swaggers. This should give some information about what client requests should look like: examples, list of input parameters, which ones are mandatory and the expected format and validation rules for each request. But sometimes it can be a bit trickier to understand, so don’t hesitate to contact EnCo and we will make a note that our documentation should be made clearer…
To make it more user friendly and easy to understand some guidelines should be followed regardless if the user is one of our customers or someone from Proximus Enco Team.
If an error or warning is returned by the front-end:
- The message needs to be short and meaningful;
- The placement of the message needs to be associated with the field;
- The message style needs to be separated from the style of the field labels and instructions;
- The style of the error field needs to be different than the normal field.
If an error or warning is returned by the back-end it should contain:
- A short and meaningful message
- Action or request which triggered the error
- A clear error code (e.g. HTTP status code)
- A unique id (transaction id, activity id, etc.)
- Date and time (incl. milliseconds) of occurrence
- Host name from which error was returned
- Extract of data set which might have led to the error
If the error still remains unclear, send us an email to support@enco.io . Don’t forget to provide as much details as possible including details described above.
Here is an example below of what is done in EnCo script. It perfectly illustrates how above back-end guidelines are followed (points 1 – 7). In this case an empty script was saved triggering a couple of warnings which can be found inside the browser console (button F12 – Network tab).
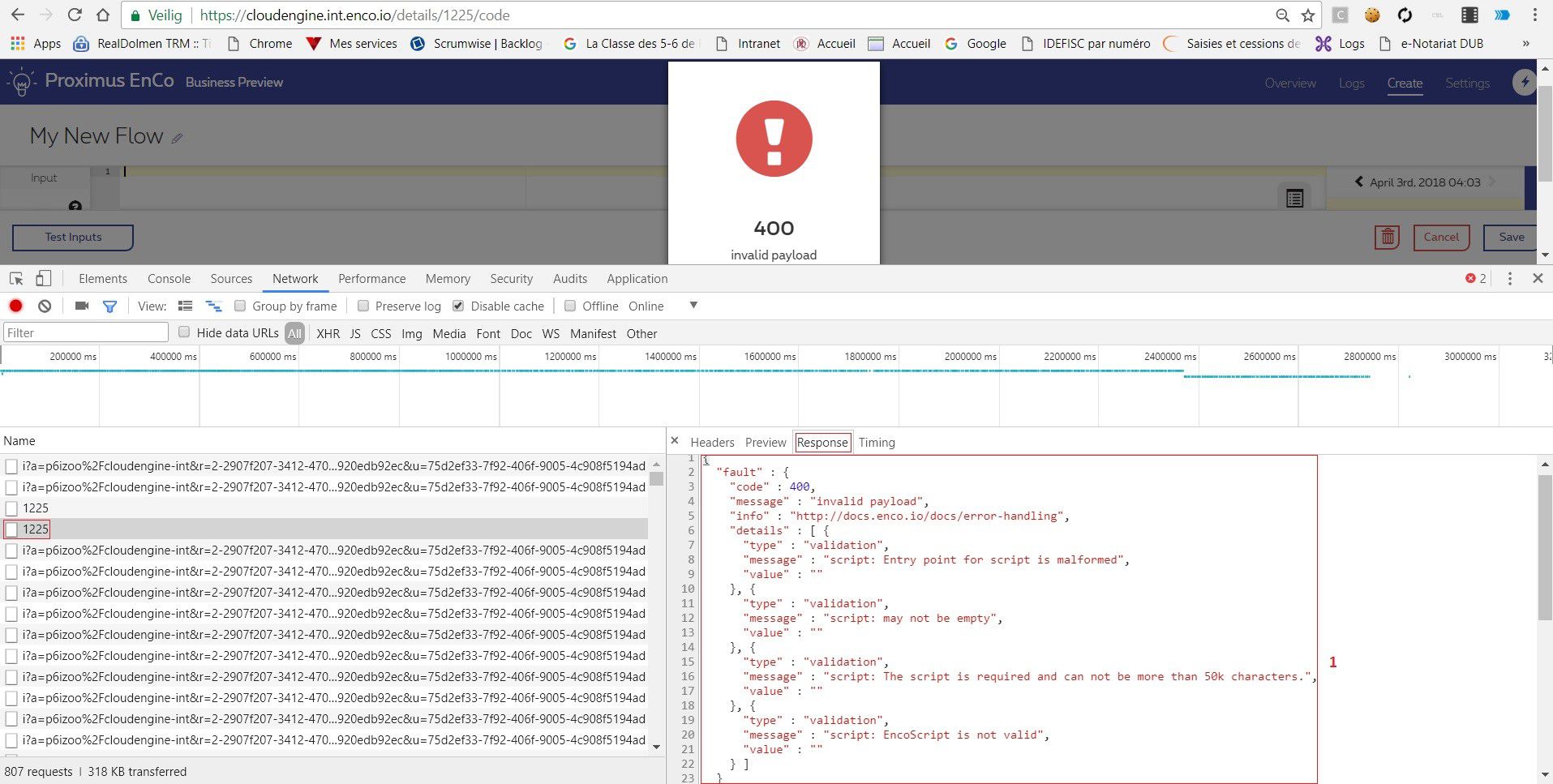
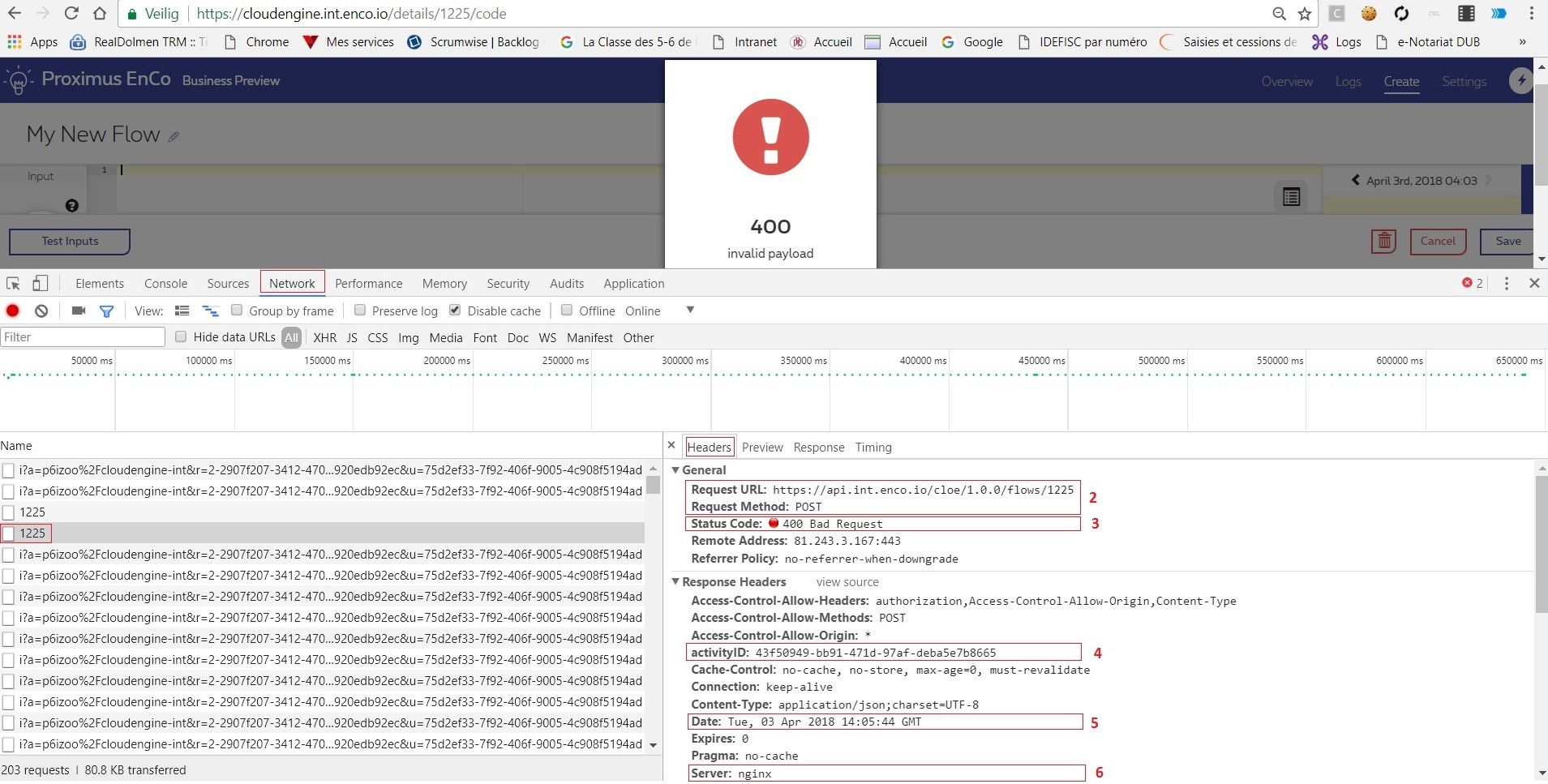
Having a look at server side, the following information can be found containing exactly the same details as on client side. Most of the time, a generic mechanism is implemented to display to the end user what’s returned by the back-end. This is to avoid maintaining different warnings and error messages on both sides!

Conclusion
As an API platform, Proximus EnCo aggregates services from various domains. It should be easy for developers to use resources from different domains without too much differences regarding user experience. Architectural decisions, technical constraints, the larger size of our portfolio and even changes to our team’s organization have had an impact on how consistent the experience is across the different assets. We reached a point in which non-written-obvious-common-sense rules needed to be formalized, agreed, written and communicated within the team.
To improve error handling, we could formally add a new set of error handling rules to our “definition of done” (https://www.scrum.org/resources/blog/walking-through-definition-done). Also, additional information could be added to error details to help our customers such as: the categorization of the error, a link to additional information and even a link to a wiki page or a forum on how-to-fix it. We also found out some more contextual information could be added. For example, when the service is downgraded information could be provided on the service status and a planned resolution time. We are currently using status.io for this ( http://status.enco.io/ ) but we could easily add a link to our status page for errors related to service disruptions. It’s also possible to fully implement the recent RFC 7807 on “Problem Details for HTTP APIs “ which defines a standard JSON object to be used in the body of each HTTP response (http://www.rfc-editor.org/info/rfc7807). This could be of real added value to the API ecosystem, making it even easier for developers to handle errors.
As a conclusion, error handling in the context of APIs is a major aspect of the developer’s experience and the final customer. This topic should be taken into consideration when designing and developing APIs as it will definitely improve the quality of service provided through:
- A clear and transparent error explanation for the final consumers
- An improved efficiency and lower costs for developers
- Easier troubleshooting at client side (faster and more focussed)
- A significant decrease in non-relevant support requests for EnCo
- More performant monitoring and troubleshooting at server side
Authors : Sid Michael Kulpok & Pierre D’Ollone